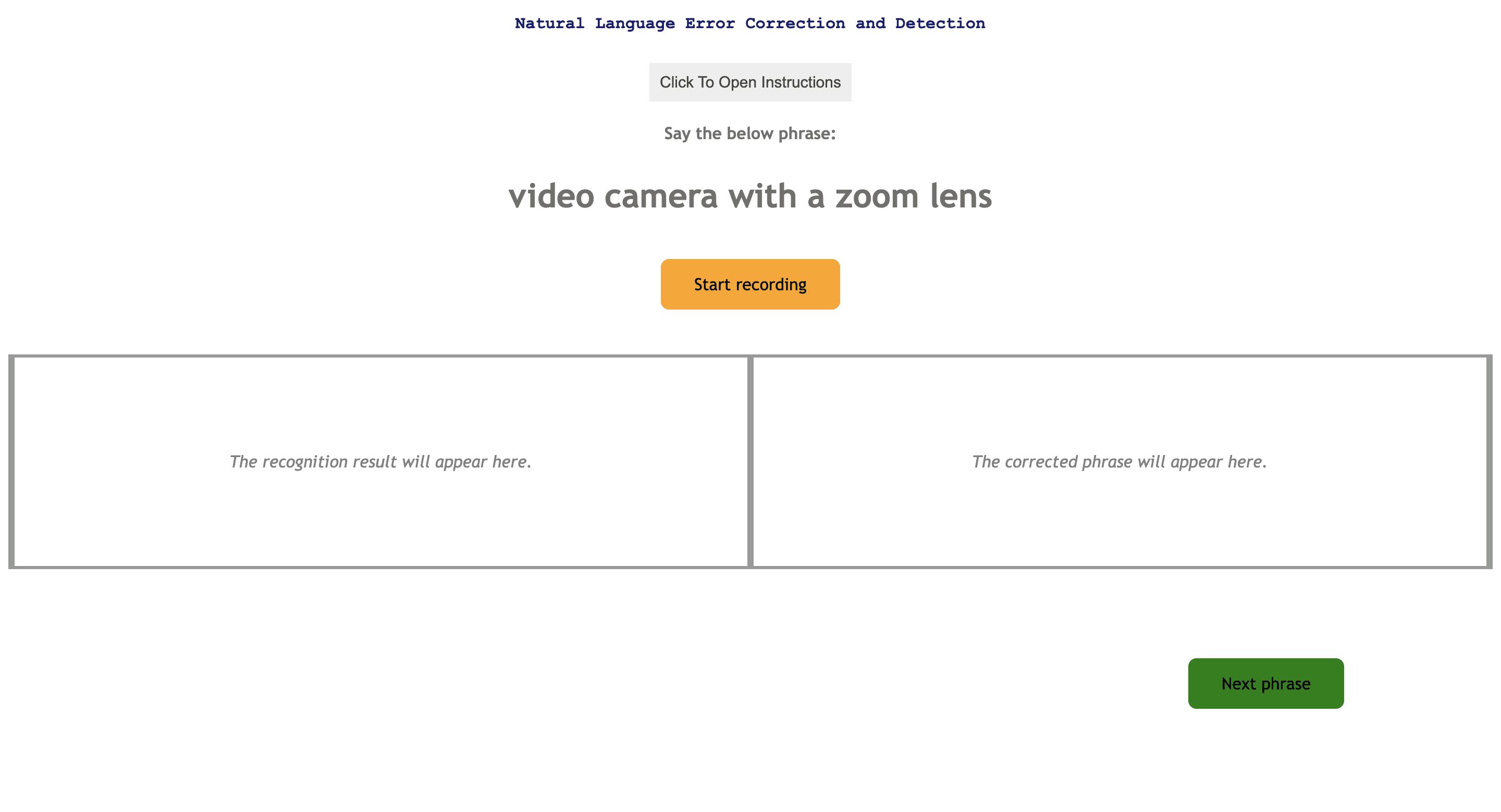
Natural Language Speech Error Correction System
Category:
SaaS Web Product
Company:
Team member:
Wolfgang Stuerzlinger (PM)
My role in the team:
Researcher. Programmer, Designer
Duration:
16 months
Voice dictation is one of the fastest ways to enter text today,
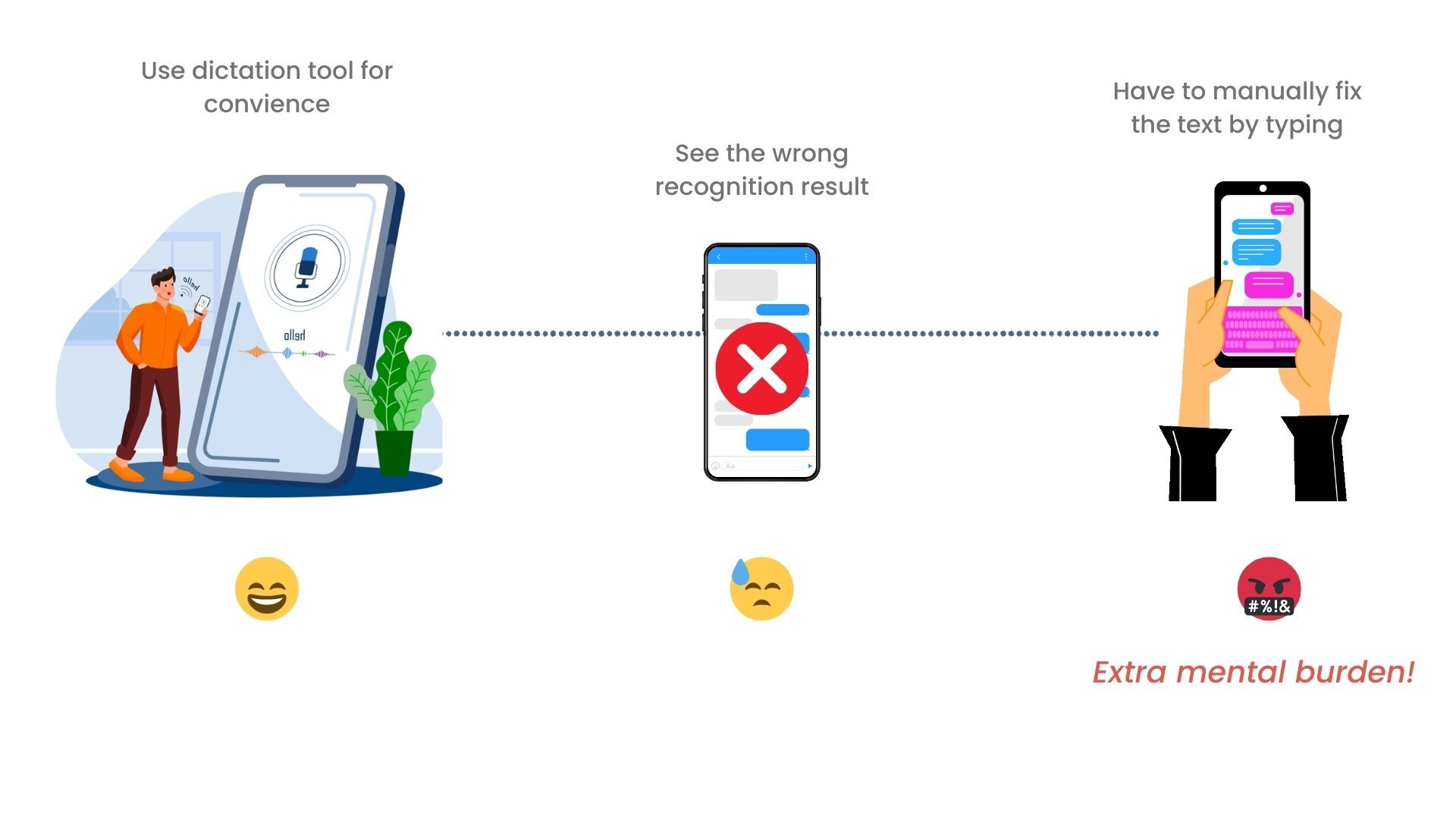
But, when the voice dictation refuses to cooperate……
Voice typing can be a bit frustrating due to errors. Usually, sighted people who can see spend around 60% of their time making edits to the speech transcription by typing. This can be mentally taxing and can discourage people from using speech-to-text interfaces as much.
💡
How might we improve the text entry experience with speech without having to manually fix the errors?
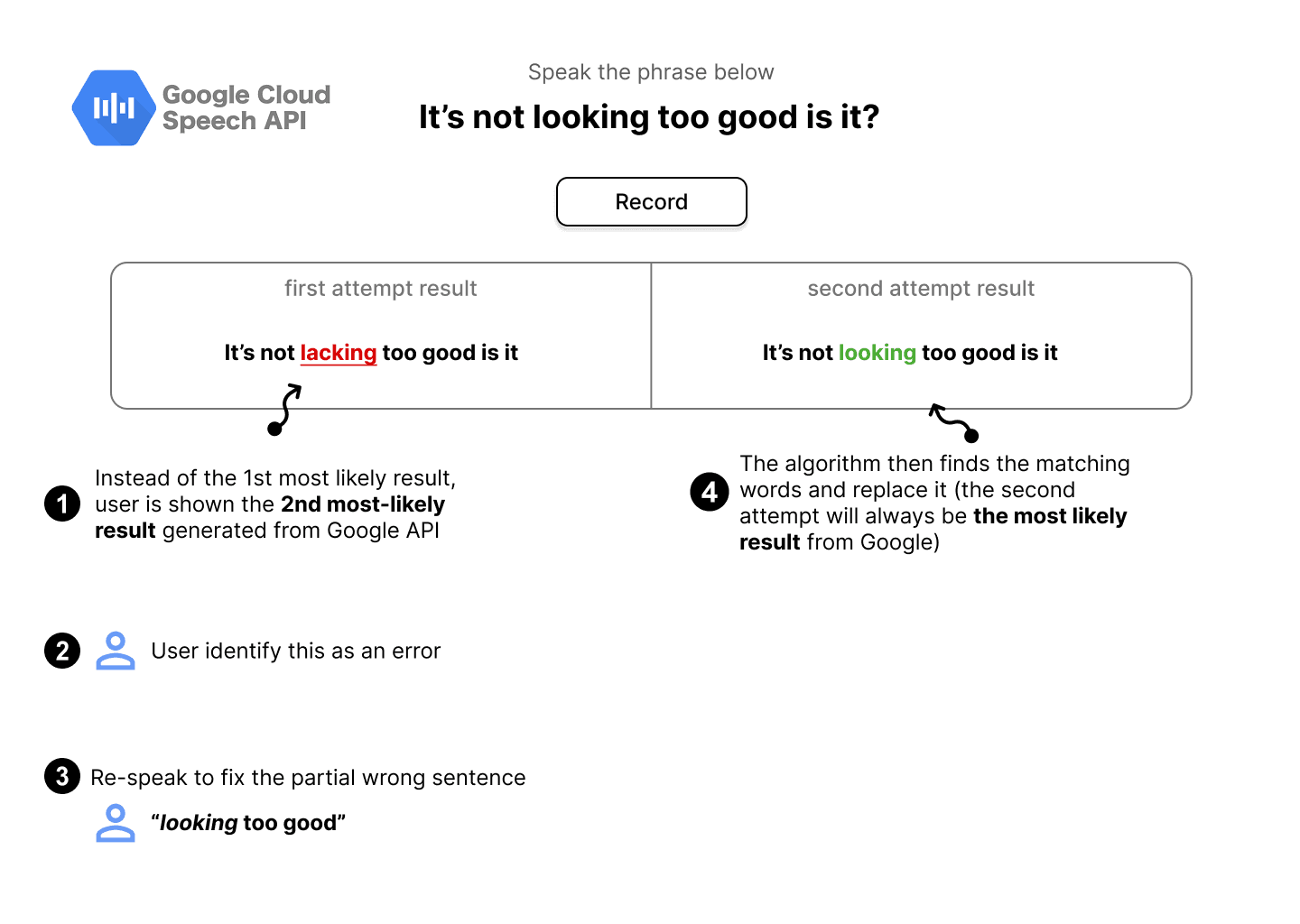
Fix the text by re-speaking
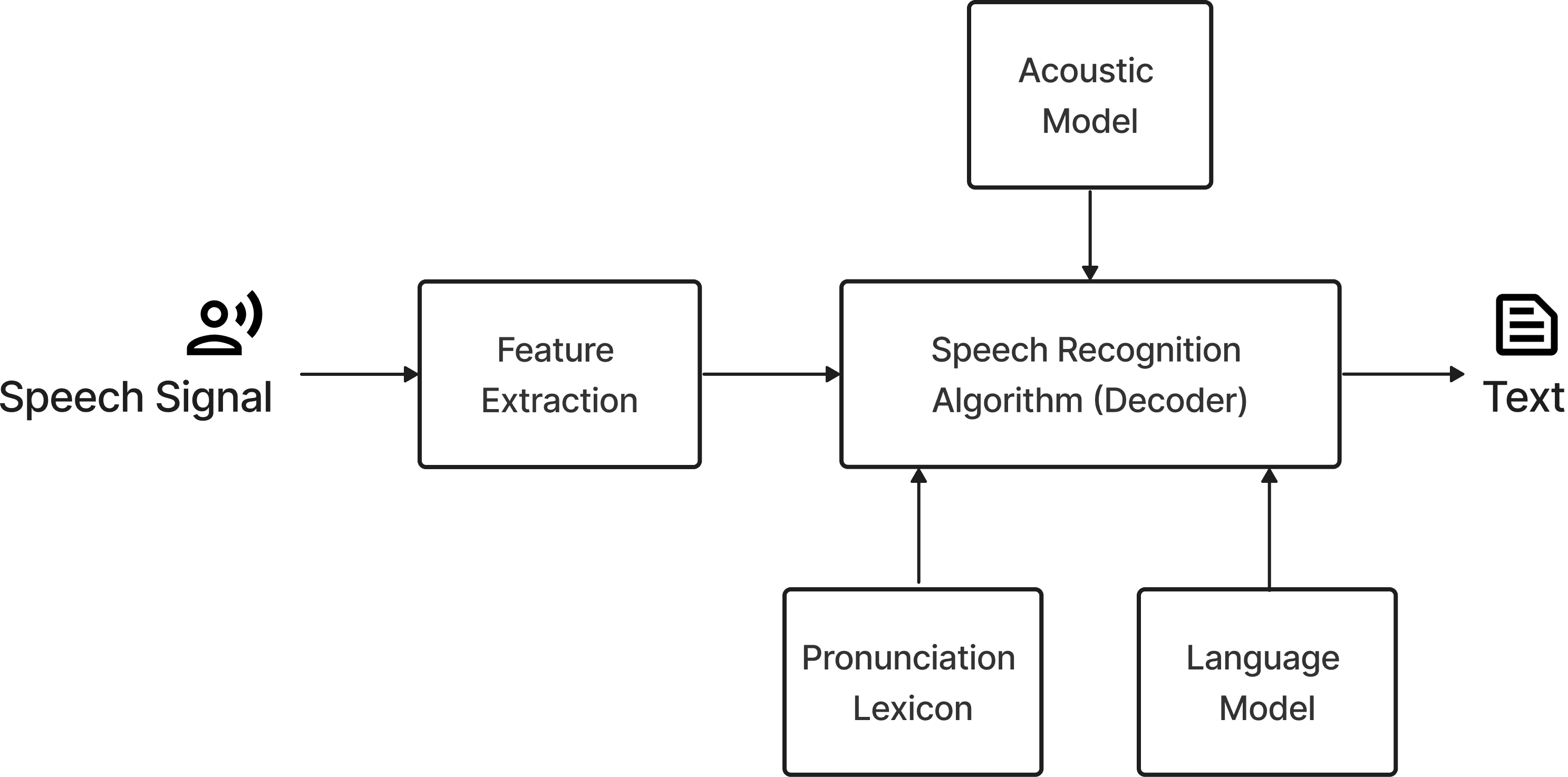
How I built the system
By introducing errors in the speech transcription, users can utilize the re-speaking feature.
Study 1: 33% of error
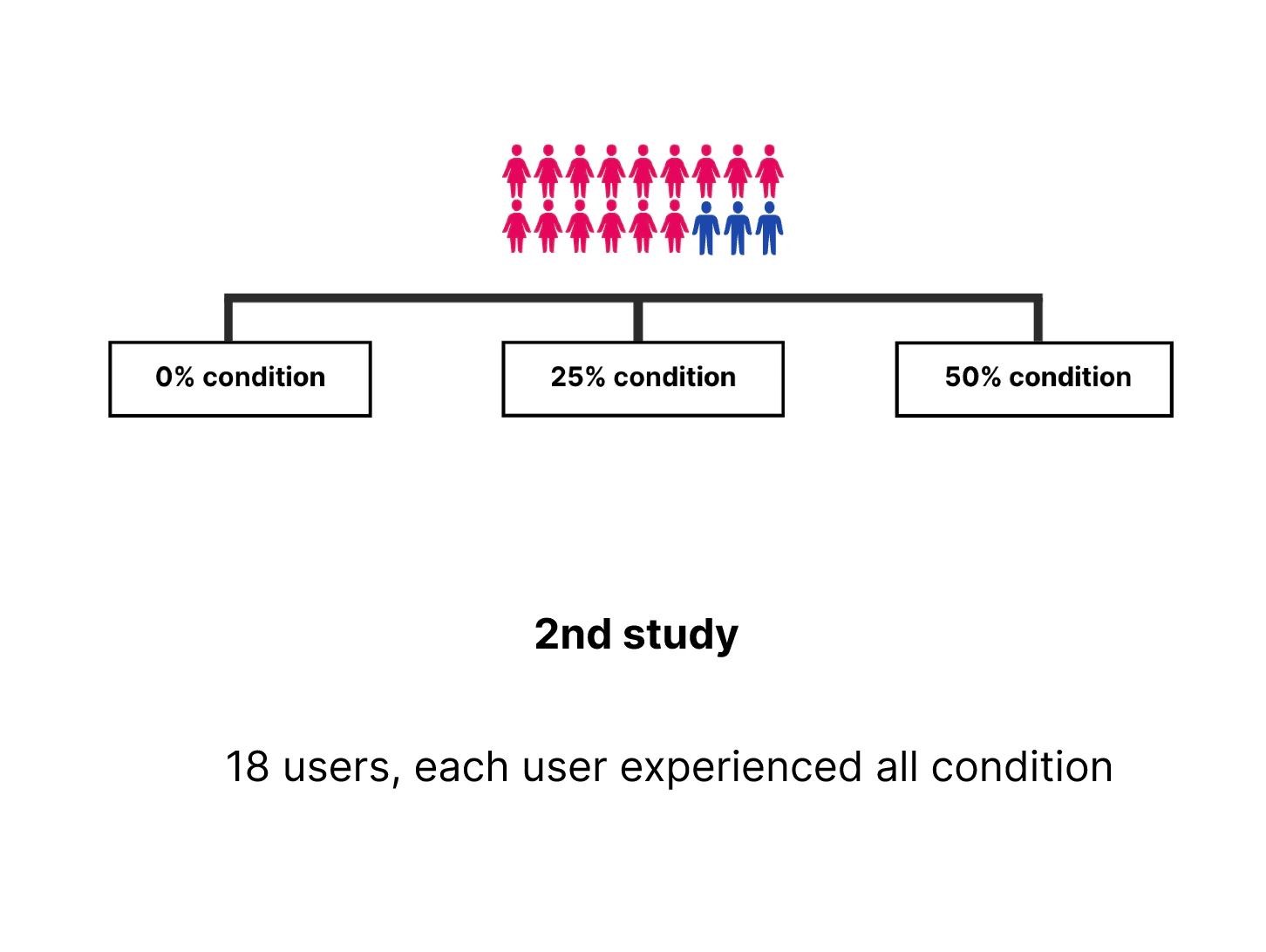
Study 2: 25%, 50%
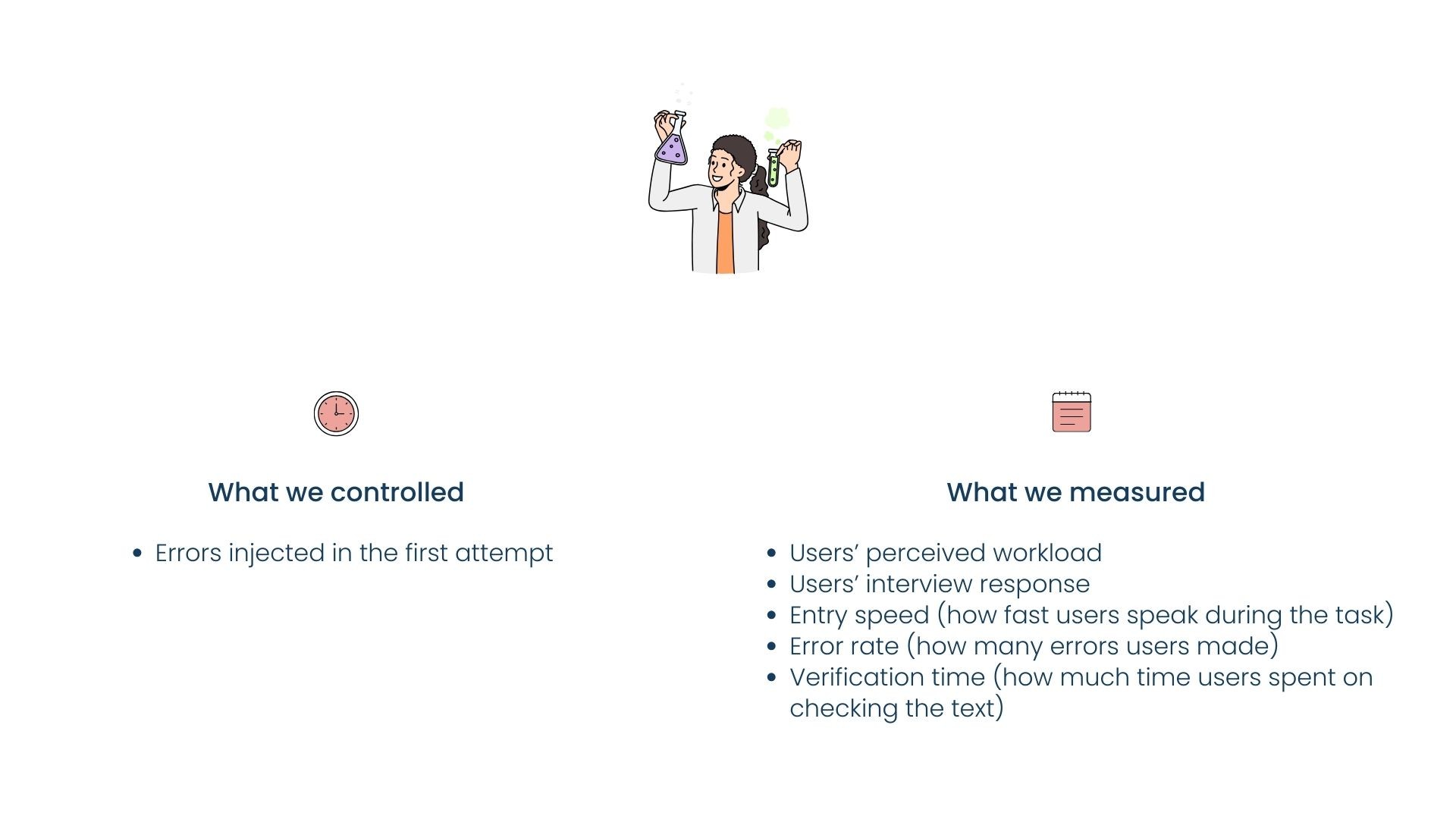
We ran two user studies with two groups of users, where Group 1 had 12 users, each completed one condition of study, and Group 2 had 18 users, each completed all three conditions of study.

The initial design of the system features a busy layout, which results in visual clutter. Users have to manually check all the boxes, potentially leading to information overload. Additionally, the CTA button is quite small, making the UI less intuitive.
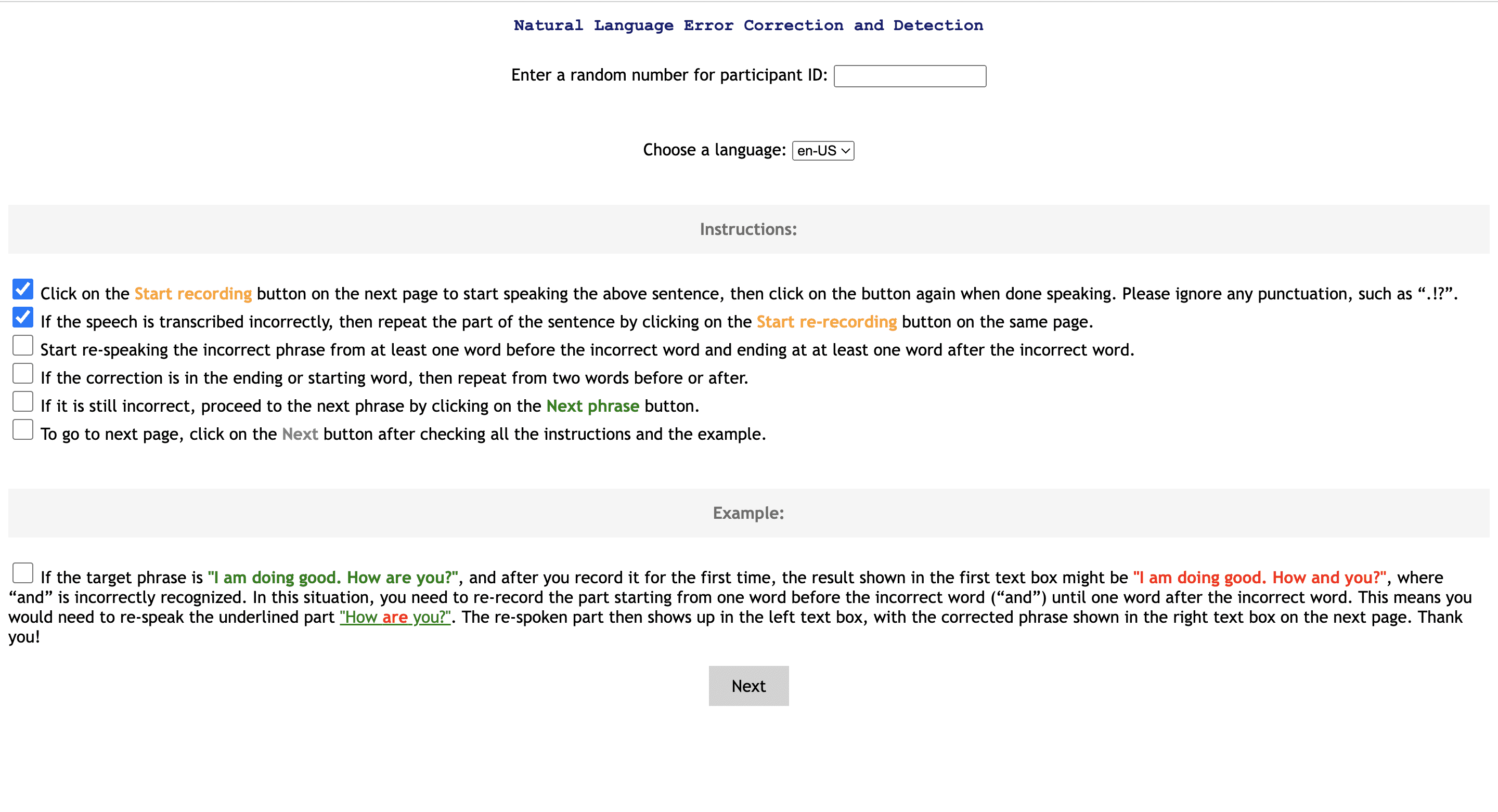
The instruction panel is distracting, lack of visual hierarchy, and fonts too small.
(USER DATA ANALYSIS)
Study 1: Quantitative result
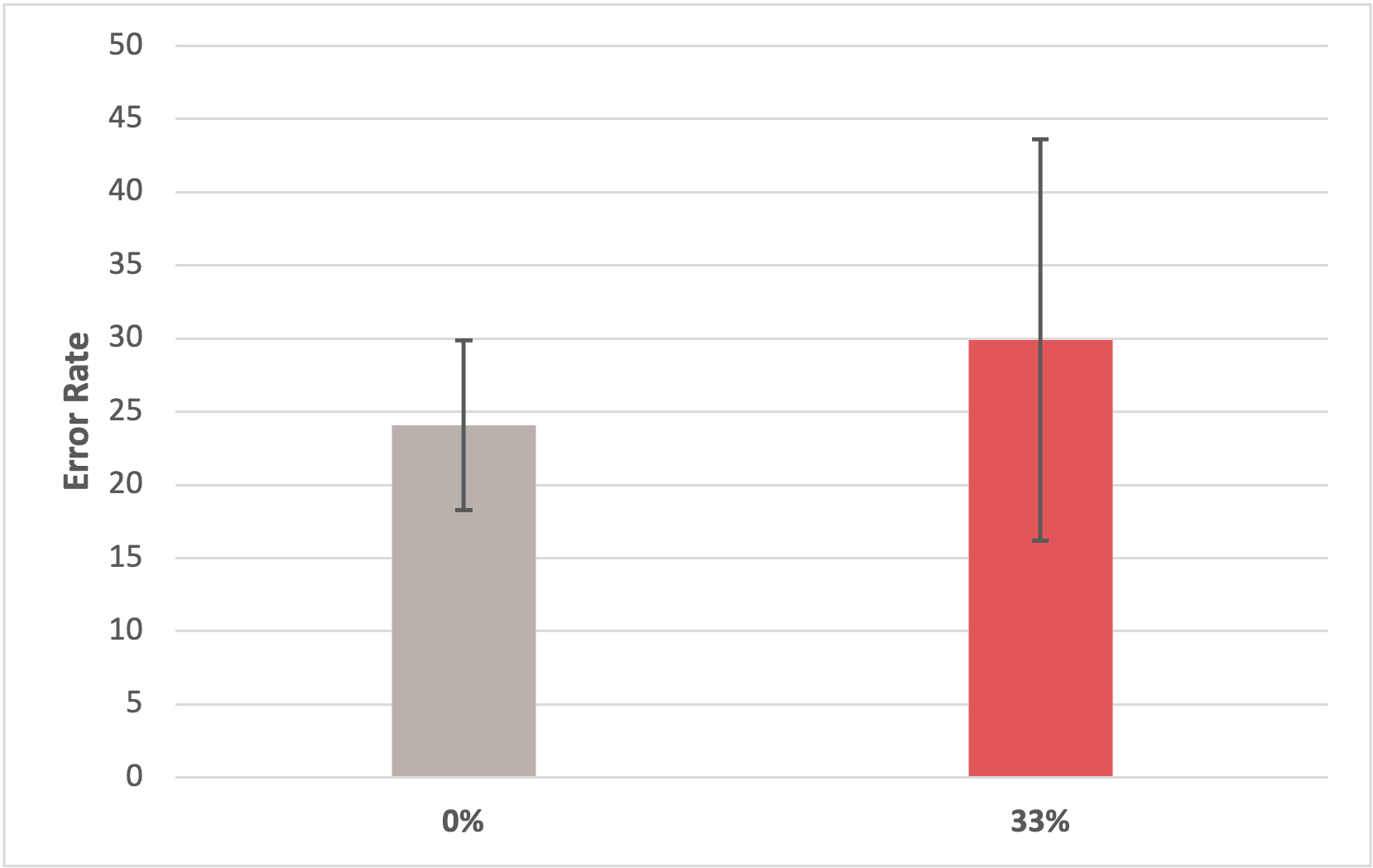
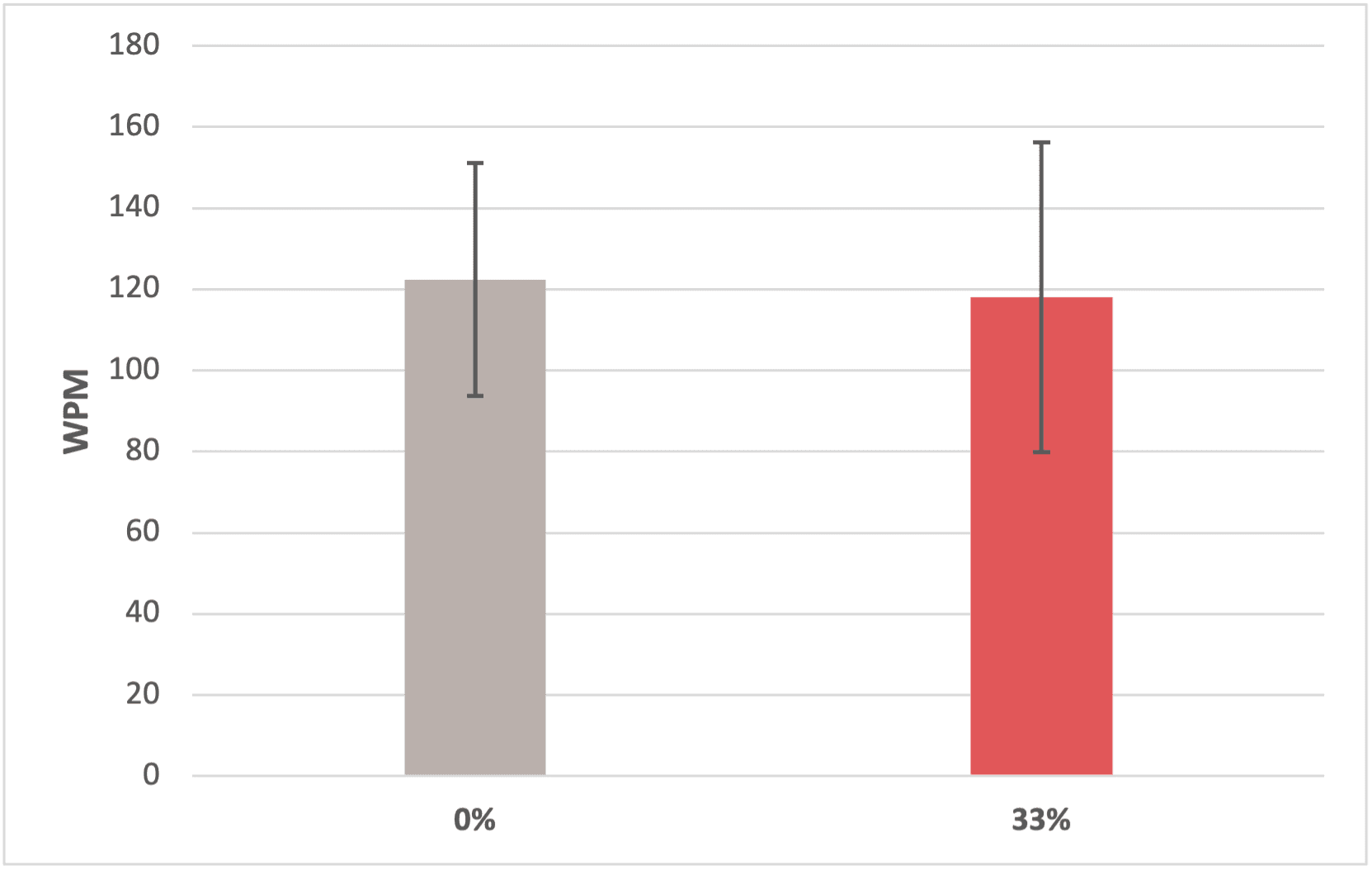
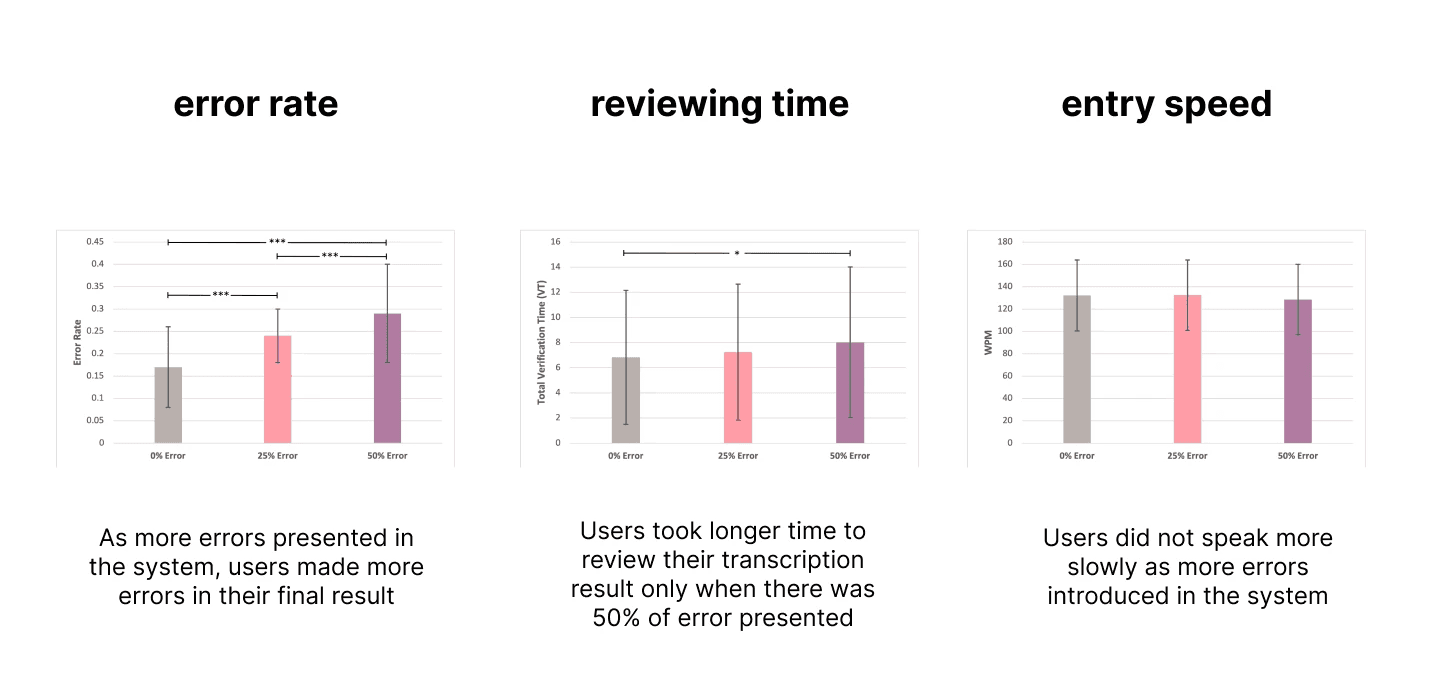
Finding #1: Inserting 33% error in the system has no significant impact on users' typing speed and error rate.
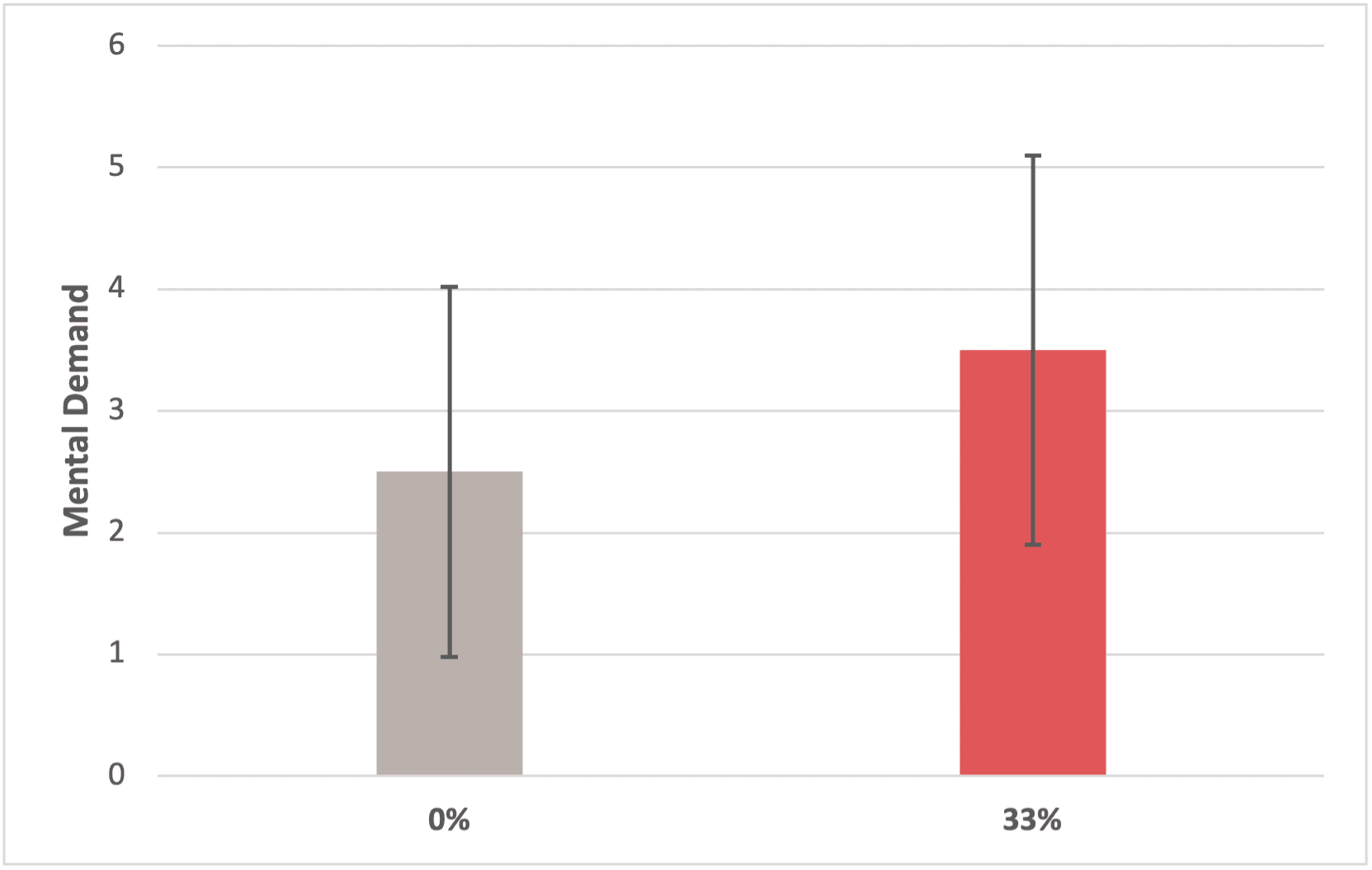
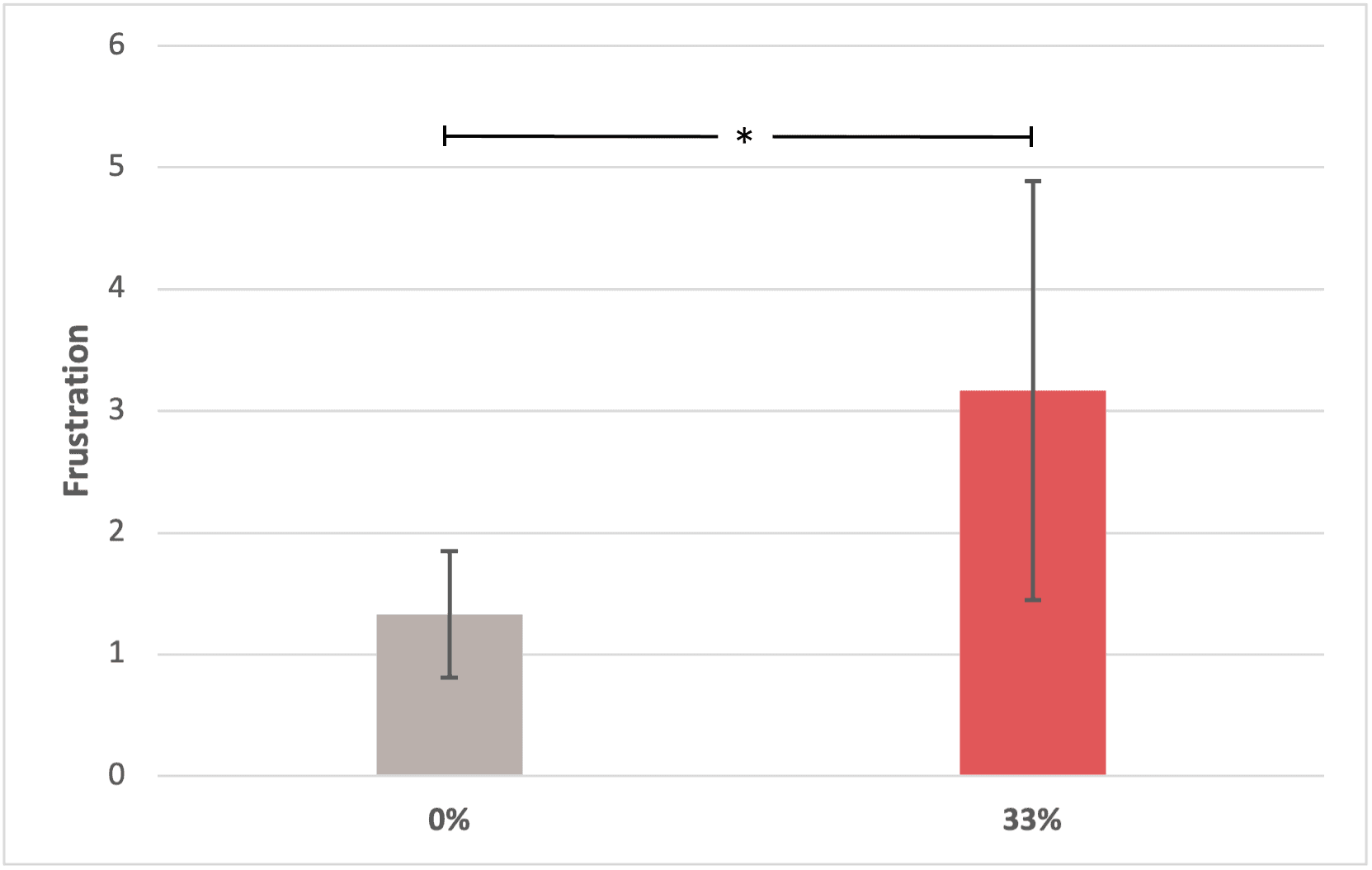
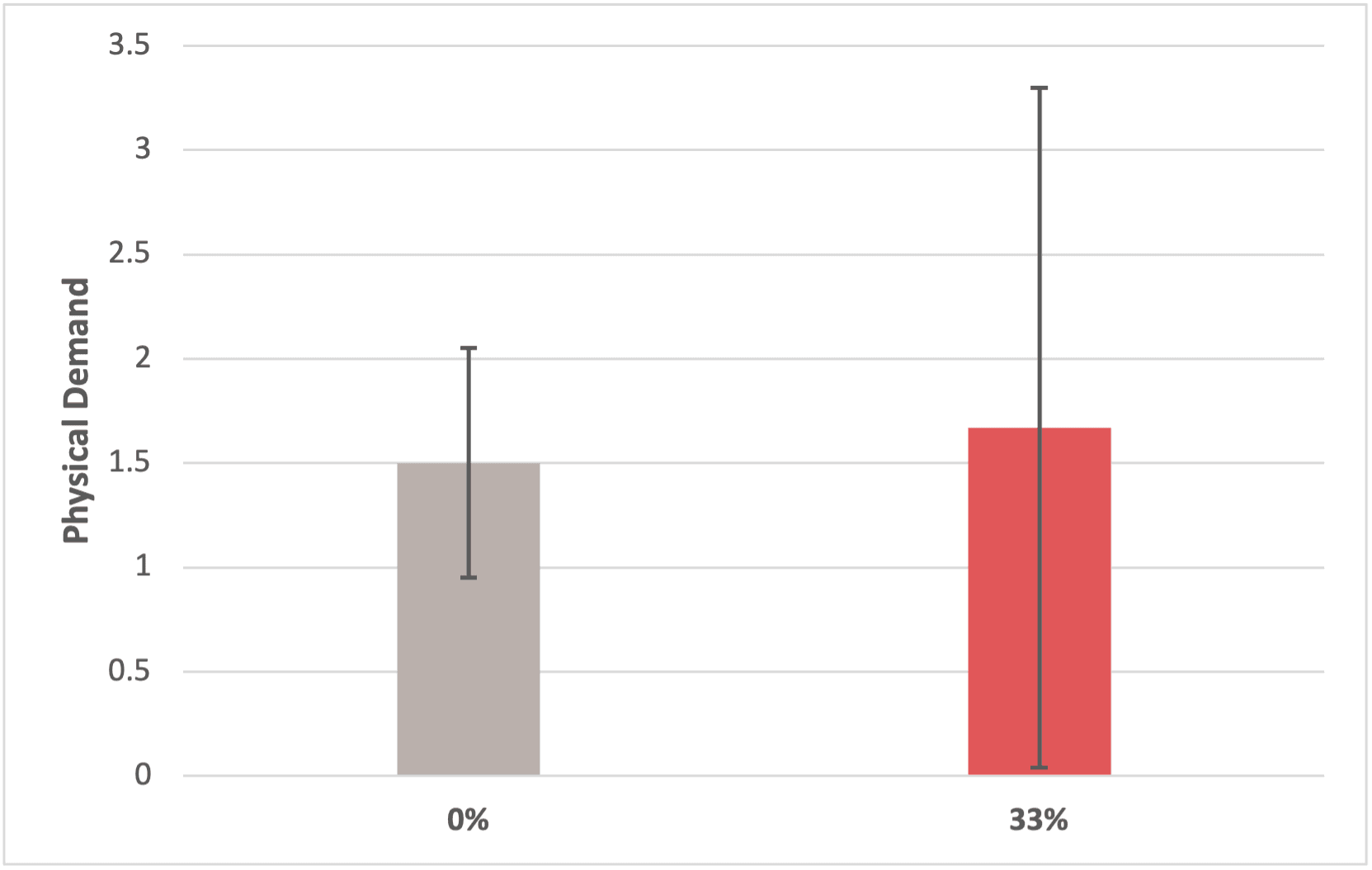
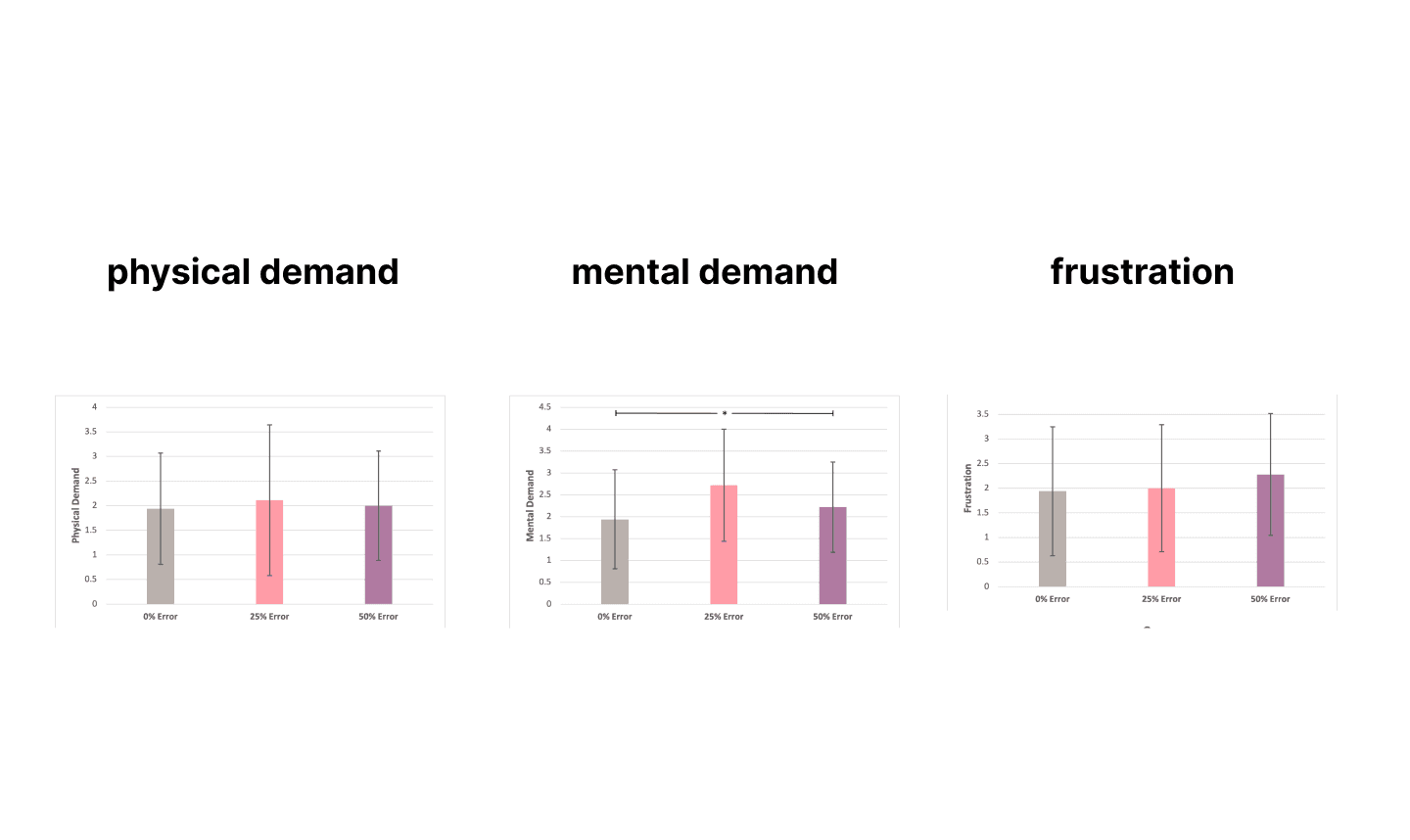
Finding #2: Inserting 33% error in the system has no significant impact on users' preceived workload and frustration.
Study 1: Qualitative result

Although users have mixed feelings about the system, we were able to identify some common patterns.
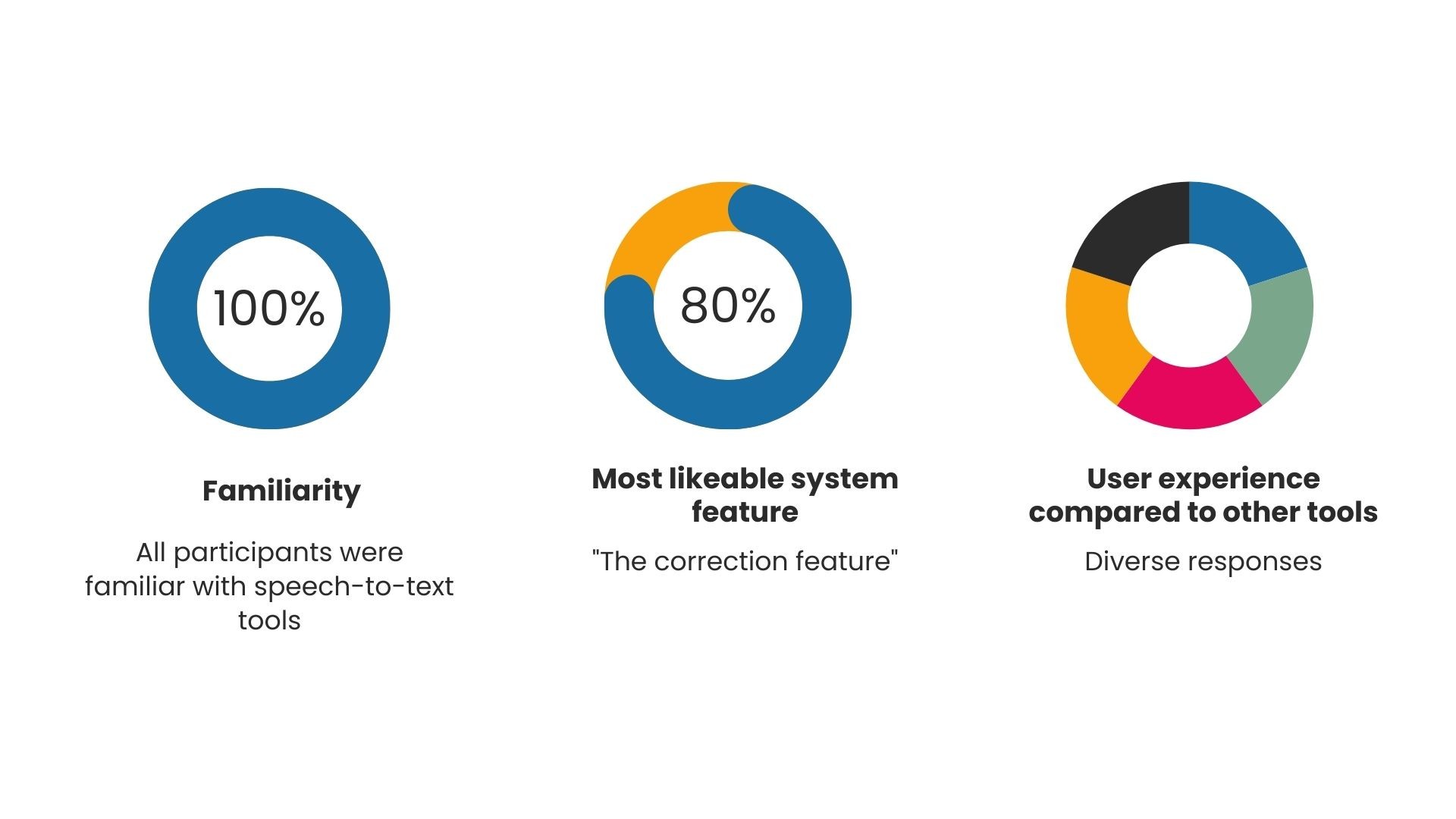
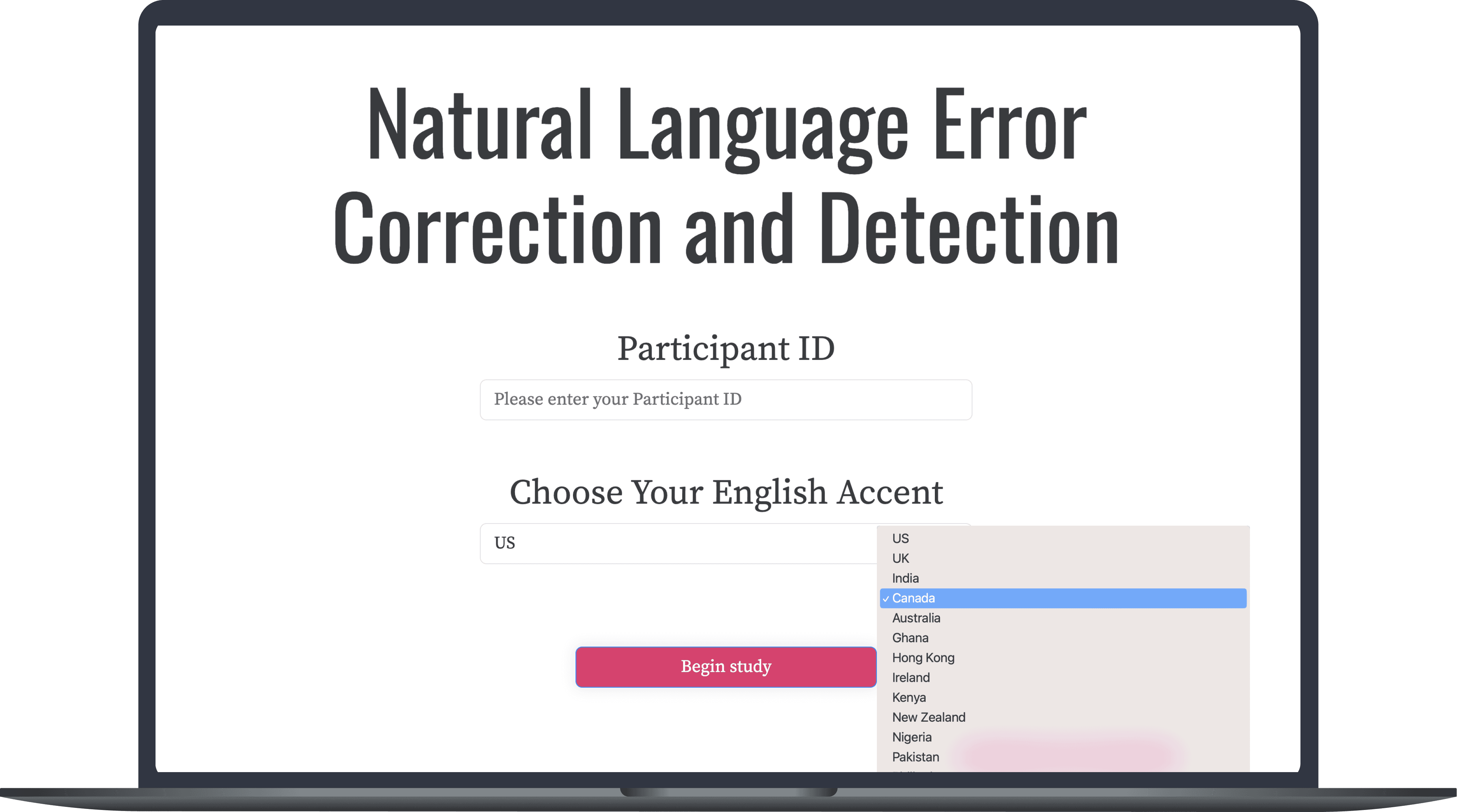
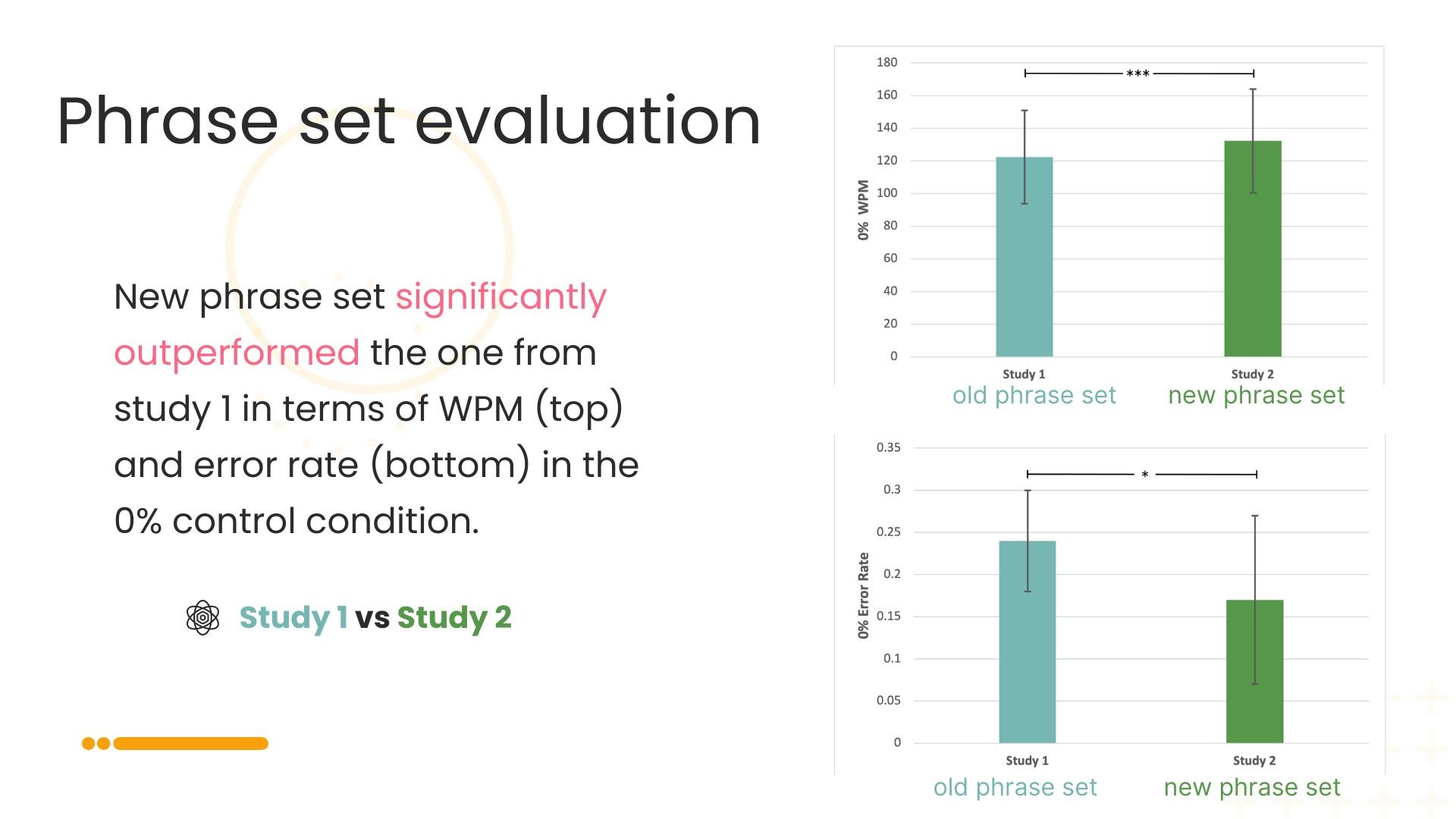
Since 80% of users had issues with the phrase set we used in the system, we decided to collect a new phrase set that is more suitable for our research, knowing that there was no existing phrase set that specifically designed for our project. We ended up with 768 new phrases.
System redesign
Front-end:
Re-programmed the code so the system ran more smoothly
Stored all user data into a clearer data table for future analysis
UX:
Created a new phrase set that collected from creditable real-life spoken transcripts
Added 12 more English accents supported by Google API
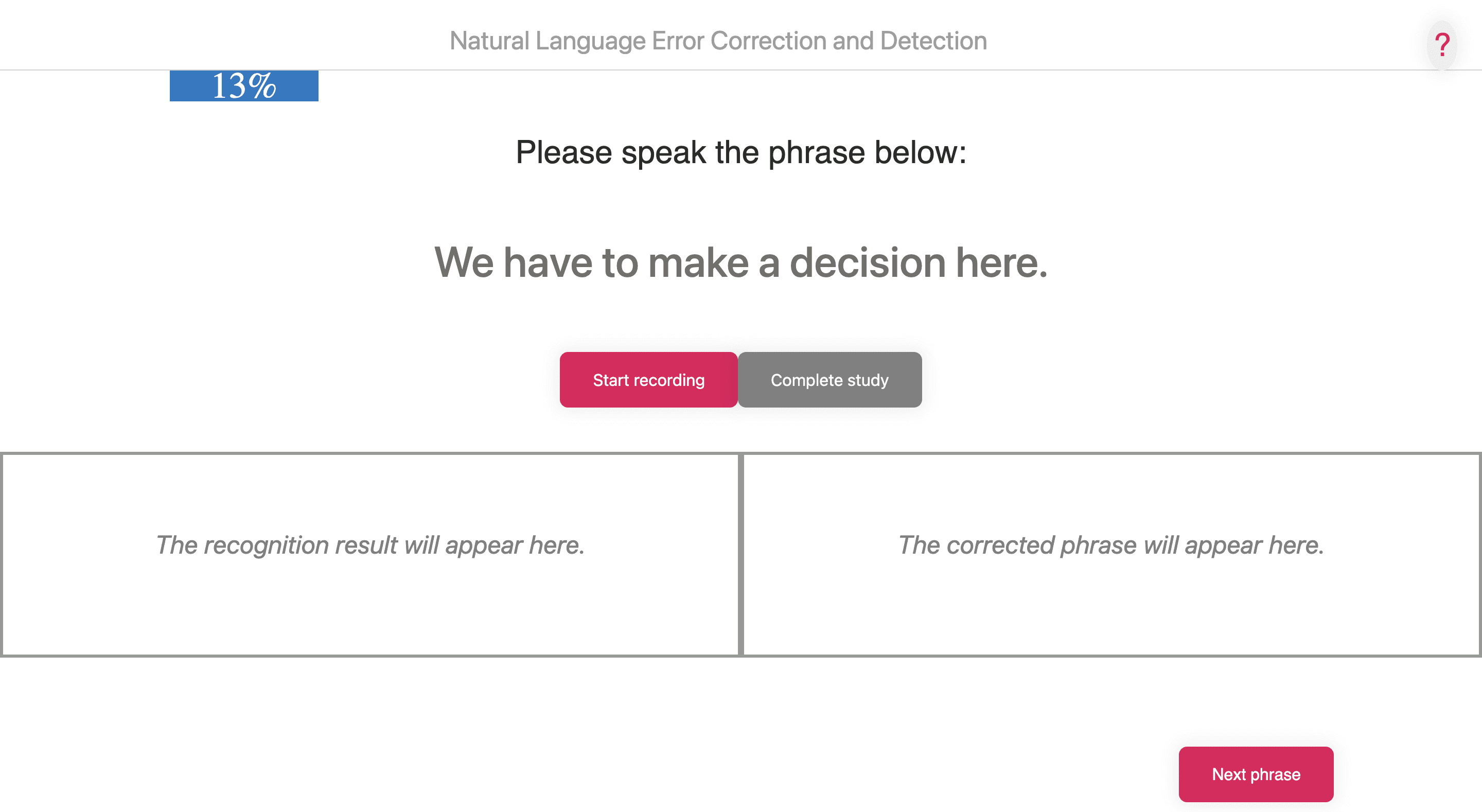
Added the progress bar to show users their current state of progress
UI:
Made the UI responsive to different screen sizes by using Bootstrap
Improved the UI by changing the layout, colours, and fonts
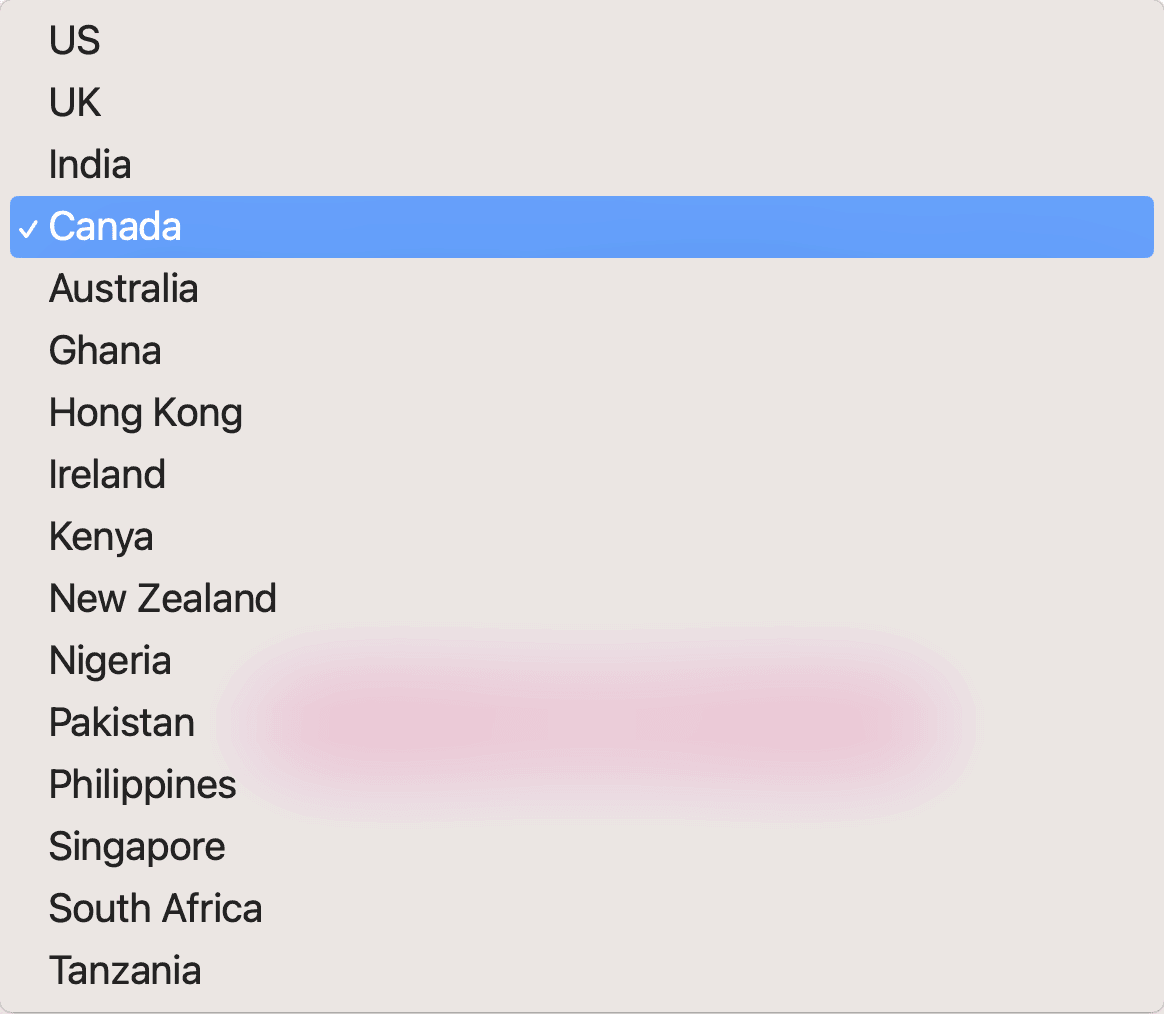
Based on the user feedback, I redesigned the UI to make it more simple and intuitive, and added additional 12 accents for accessibility.
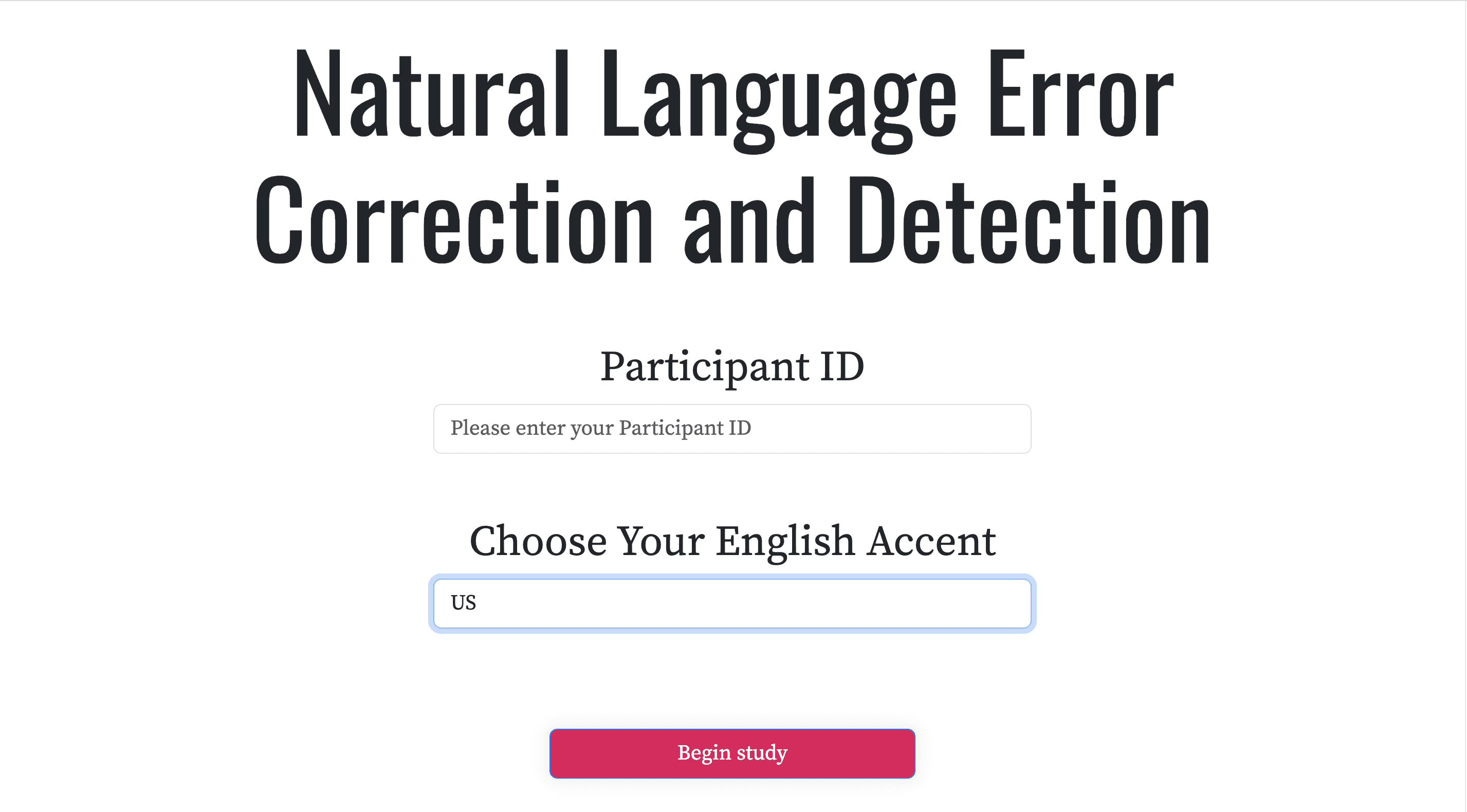
I also added the progress bar and hide the tutorial for ease of use.
For Study 2, we re-tested our system with another 18 users.
📊 Results
Quantitative result
We added another metric as reviewing time to measure how long does it take users to review the recognition results before moving to the next phrase.
Finding #2: Inserting 33% error in the system has no significant impact on users' preceived workload and frustration.
Easy of use:
Preceived workload:
Qualitative result
We added another metric as reviewing time to measure how long does it take users to review the recognition results before moving to the next phrase.


No obvious learning/fatigue effects
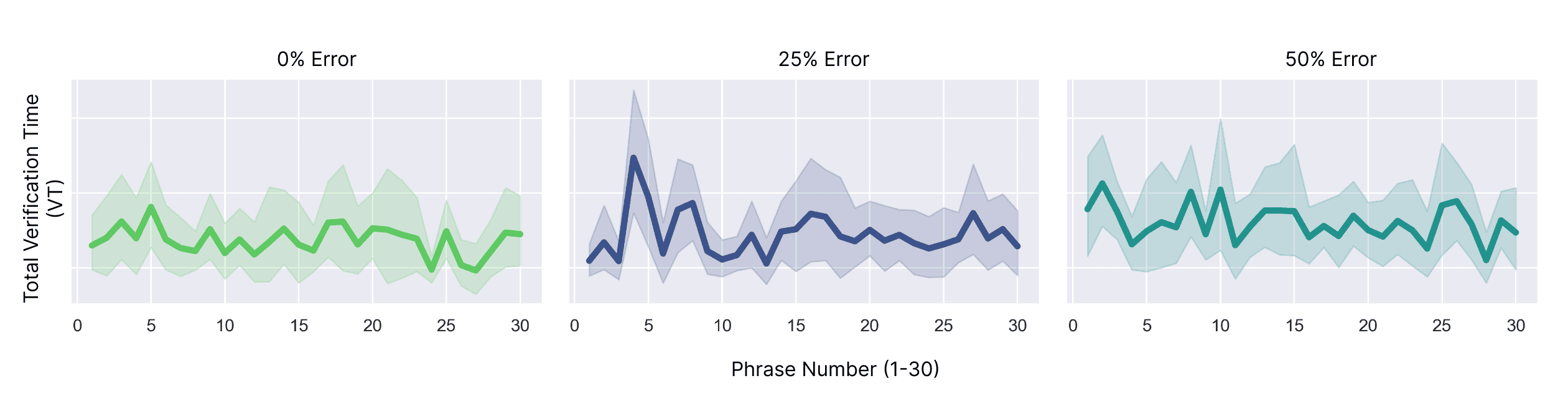

We looked at the verification time and word per minute, but we did not observe a consistent pattern for potential learning or fatigue effects.
🌱 Product success
We added another metric as reviewing time to measure how long does it take users to review the recognition results before moving to the next phrase.
Dig deeper:
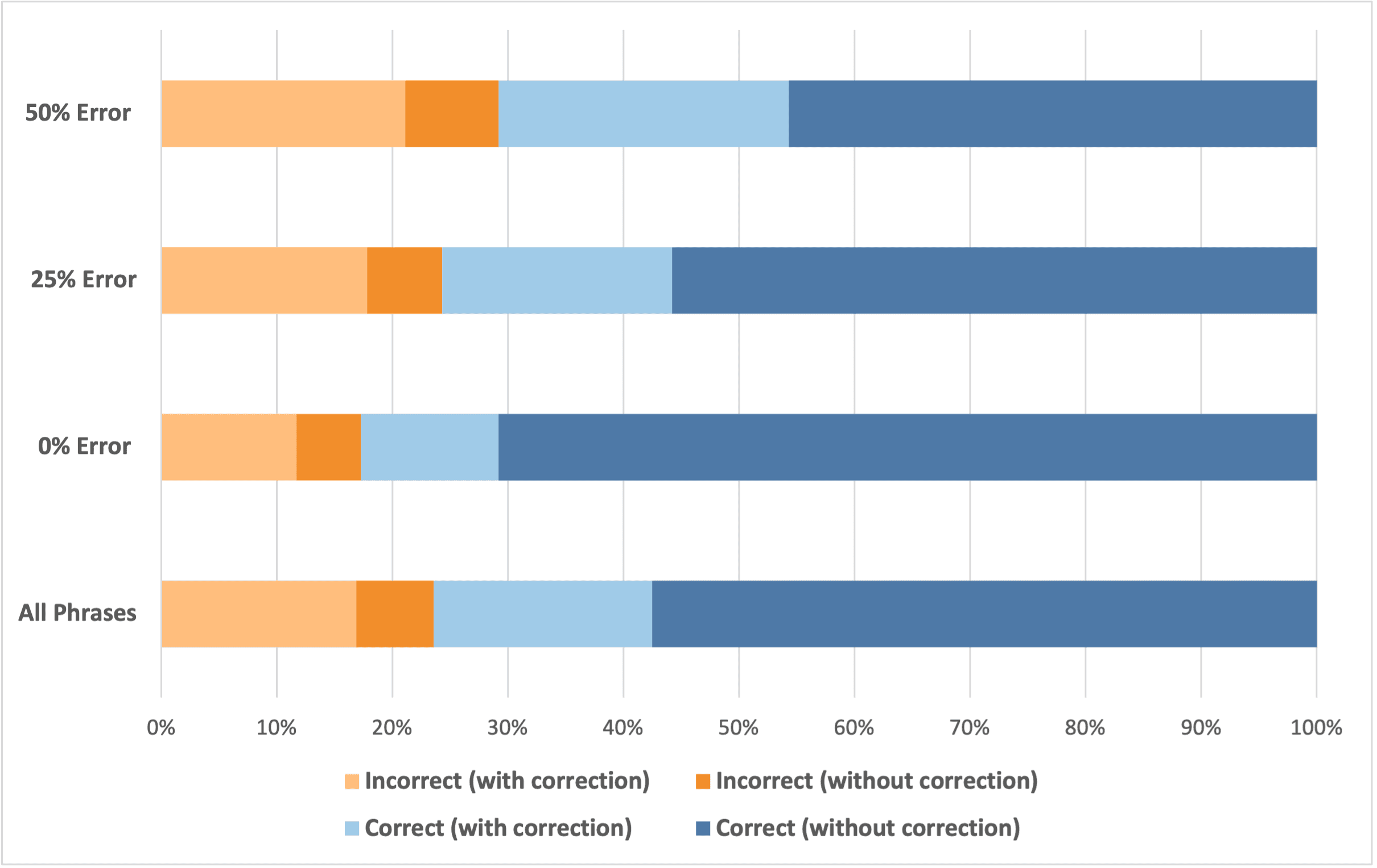
To further explore the user behaviour, we examined the different error outcomes in the final submitted phrases. Based on the final submitted text, there were four different types of outcomes. The text could be either correct, as indicated by the blue hues or incorrect, as indicated by the orange hues. Participants could have also either used the correction attempt, indicated by the light tones, or got the phrase correct at the first attempt, indicated by the dark tones,
Hence, the dark orange hue is of specific interest, which indicates episodes when the final text was incorrect but participants did not use the correction attempt. We call this an identification error, because it means participants failed to identify the errors in the first recognition result. We found that as more errors were induced, participants were more likely to make such identification errors.